
Status of Attaca: March 2018
Last year I made a post about Attaca.
Attaca/Subito is a distributed version control system for large repositories. The project is supported by Mozilla under the Open Innovation team. Since I last posted about it, I’ve taken the project to SCALE 16x, talked to potential users, and learned a lot both about constraints on the project itself and the people who are interested in it. First, a little update on where we are with the project:
Milestone 3
As of March 2018, I’ve completed the third milestone of my initial goals! It took a lot longer than I expected (and a lot of trial and error.) At this point, Attaca was supposed to be a demo-ready system, essentially minimally usable. While it is a demo-ready system now (and arguably minimally usable) I would not advise it. Why?
- It does not meet my standards for robustness.
- It will not warn when it decides to overwrite data with certain commands, and hence is dangerous to use. No one wants to lose their work.
- Minor architectural changes and major changes to object encodings are about to happen. Hopefully, these encoding changes are the last to happen before we decide to begin stabilizing things.
So with that aside, let’s go a little further into the details. What does Attaca look like now, and how is the implementation different from what we want it to look like? And what challenges have these goals presented?
Attaca now vs. Attaca goals
Currently, Attaca/Subito (previously simply named Attaca) consists of two parts. These parts are Attaca, a content-addressable storage system with some desirable properties for large quantities of data and data integrity, and Subito, which is a version control system built on top of Attaca. Things look something like this:
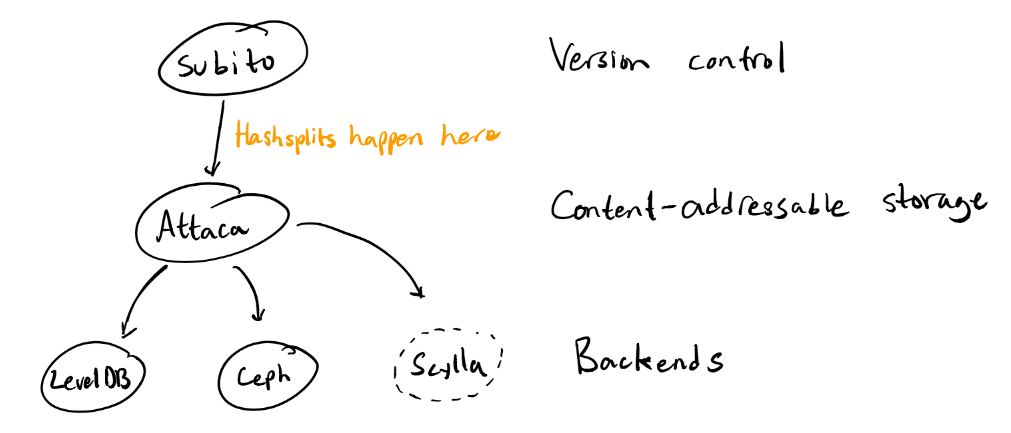
This is non-optimal for a few reasons. The main reasons have to do with the underlying content-addressable storage system: as it is now, the underlying store is forced to support branches, which clash badly with the idea of an immutable content-addressable store. After thorough discussion, the point has been convincingly made that branches (and atomic branch updates) are separate functionality from the underlying content-addressable store and should live in a separate abstraction. This results in two much cleaner abstractions, including a much nicer API for garbage collection of no-longer-needed objects in the underlying content-addressable store. It also allows for convenient separation of the consistent branch store from the not-necessarily consistent underlying object store.
In addition, note that the conspicuous orange “hashsplits happen here” text appears above Attaca: at current, hashsplitting happens before objects are written to the store. This will soon change:
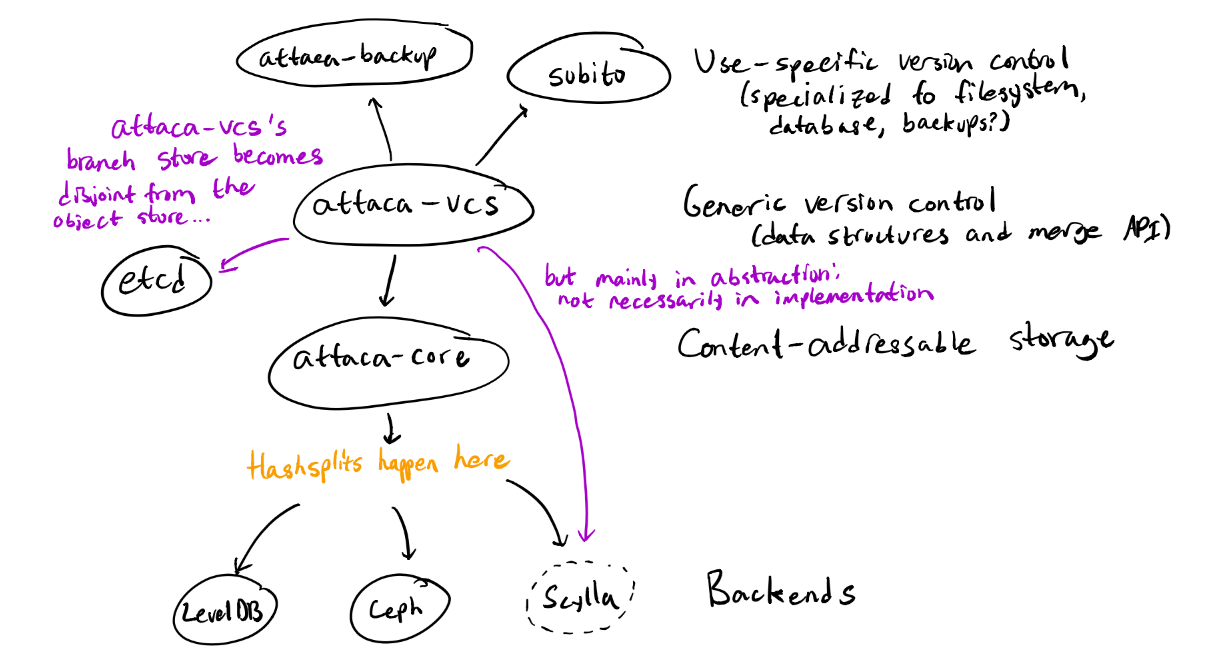
The above image roughly illustrates what things will eventually look like. The Attaca store becomes two separate crates, attaca-core and attaca-vcs:
- attaca-core: the content-addressable store backend with internal hashsplitting and hash-agnostic deduplication, supporting efficient, asynchronous data transfer
- attaca-vcs: extensible version control data structures (blobs, trees, commits) along with a generic merge API defined over them and basic merge strategies; the consistent branch backend, supporting atomic compare-and-exchange
This will mean that Attaca/Subito will essentially have three main components:
- The underlying attaca-core crate will be usable as a content-addressable store with all of the desirable properties from the un-split store (including hash agnosticity and with the addition of internal hashsplitting.) It will also support a simple and robust API for performing garbage collection on the underlying store.
- attaca-vcs will be usable as a generic version control system unspecific to the actual applications of the underlying system. The intent is to have a useful VCS framework which is detached from specific notions of filesystems/permissions/other data aside from the basic concepts of blobs, trees, and commits. It will also contain functionality for “branch backends” supporting the necessary atomic operations.
- subito will be usable as a frontend built on attaca-vcs which produces commits/trees/blobs annotated with the relevant filesystem metadata (i.e. file executability and blob types, in a similar manner to Git modes.)
In addition, it would be useful to have a backup system built on attaca-vcs. Such a system would be similar in function and use to tarsnap, a backup tool which also performs hashsplitting under the hood. With attaca-vcs it would be simple to build a tarsnap-like utility.
Challenge: extensible object metadata
One issue with the split between attaca-vcs and subito is that of extensible blob/tree/commit metadata. There are a few ways we could solve this: one of the current possible solutions we’re looking at is actually RDF, the Resource Description Format. RDF is a standard for “linked data”, which happens to be exactly what we’re looking with an object store like Attaca’s; the store forms a directed acyclic graph where nodes are objects and edges references from one objects to another.
RDF solves one particularly annoying problem with extensible metadata: the issue of colliding identifiers. Suppose one version control system built on top of attaca-vcs wants to add a “location” property to its commits, encoded as latitude and longitude, for encoding the physical location which some commits originated from. Then, another system built on top wants to store a URL as the “location” property, indicating some location on the internet which the commit came from. If the second system attempts to read objects created by the first system, it will end up finding “location” values which look malformed, instead of simply finding that the “location” property wasn’t set for a given commit (which might be a recoverable error.)
This is solved in RDF by making identifiers IRIs: IRIs are a superset of URIs (which are a superset of URLs). This means that if you want to create an identifier for some given property of, say, a commit, you would define it as an IRI in some domain that you own. For example, for the “authors” property of an Attaca commit, I might use the IRI “https://attaca.io/2018-attaca-vcs#commitAuthor”. Since I own the domain https://attaca.io, my use of the identifier is the only valid usage, and if for some reason someone else wants to create a “commitAuthor” property, it can’t collide with mine, because if they want their IRI to be valid, they’ll need to allocate it to an IRI under a domain they own.
There may be other options, but RDF currently stands out as a highly appropriate solution, given the structure of an attaca store. It also happens to be standardized, and if there’s one lesson I’ve learned recently, it’s that standards exist for a reason. There are some issues with RDF which need to be resolved, such as finding canonical forms of RDF graphs in order to nicely hash them. RDF canonicalization algorithms exist but are hash-dependent, which would mean that the underlying attaca-core store would need to understand RDF and be capable of canonicalizing it as preparation for hashing with a given digest. This is a tradeoff and is still being considered.
Challenge: garbage collection API
The original Attaca garbage collection API was going to be something along the lines of “delete all objects not reachable from the current set of branches.” With the separation of the branch set from the content addressable storage system, this no longer makes sense. Without going too far into detail, the new API will look like two methods: one to report the “root set”, and one to do an atomic compare-and-exchange on the root set. Here, the “root set” is the smallest set of objects from which all other objects in the repository are reachable: straightforwardly, an atomic compare-and-exchange on this set means that all unreachable objects can be immediately deleted. This is much more elegant than the “branch set” for a number of reasons, the most obvious of which being that the branch set is specialized to version control applications (and also, branch operations were not directly related to garbage collection operations. It was unspecified when garbage collection might happen.)
Challenge: robustness/safety of the Subito UI
I knew it wasn’t going to be easy writing a version control system, and I wasn’t disappointed. One of the hardest parts of doing so is ensuring that unsaved data is never lost: data loss, after all, is the worst kind of failure a VCS can possibly have. This is one of the main reasons Subito is not currently ready for use. Run the wrong command and it will happily overwrite files in your workspace without a single objection. This is partially due to how the current proof-of-concept UI is extremely ad-hoc. Subito will soon need a well-designed UI, and unfortunately UI design is not my forte. This is absolutely a space where I would like to ask anyone with relevant expertise or experiences to contribute their thoughts to the project.
Challenge: hashsplit “extents” API
Moving hashsplitting underneath the content addressable store means that tools built on top of attaca no longer need to directly deal with hashsplitting. However, knowledge of hashsplitting details can be useful for building programs which want to efficiently deal with mutating large files, especially with something like a FUSE backend: if a write occurs, it’s useful to know exactly which hashsplit chunks it occurred in, because then we can perform a more efficient update to the underlying object. Instead of rewriting the whole object, we might ask the store “please remove these chunks, and replace them with these new chunks.” To make this possible, an API needs to be designed for efficiently accessing and manipulating the underlying “extents” of an object in the content-addressable store: it should support finding the “extents” corresponding to a range of bytes, as well as creating a new object by operating on hashsplit extents. As of now, this design is still pretty vague, and notably isn’t necessary for a working attaca-core, attaca-vcs, and subito, so it’s pretty low on the priority list.
Contribution
Interested in contributing? The Attaca repository recently moved from a repository under my Github username to a fresh “attaca” Github org. The new repository can be found at https://github.org/attaca/attaca. Design documents will eventually be moved from transient private chats into markdown documents stored in the https://github.org/attaca/rfcs repository; it may take a little while for things to show up there, since we’re still ironing out some details. In addition:
- I can be found under the nick
sleffyin the#attacachannel on irc.mozilla.org. Ping me if you want to chat about Attaca! - We have a mailing list strictly for announcements here.
- We have a Slack server; click here to join.
Attaca is written in Rust. If anyone is interesting in contributing some Rust code but is new to writing Rust, I am willing to mentor them through the process.
Hope to see you around!