
Large Files, Version Control, and Hashsplitting
I’m currently working on Attaca, a fast, distributed, and resilient version control system for extremely large files and repositories, designed for scientists working on projects containing terabytes or petabytes of data. (Warning: not currently in any sort of working condition as of 8/29/17!) There are a few key components to this design; the first is the git data structure, with one special modification. The second is a distributed hash table (DHT) which is used to store the objects of the graph data structure, and the third is a technique called “hashsplitting” or “hash chunking”. Resilience is handled by the distributed object storage system, and version control itself by the git-like data structure.
The reason for borrowing the design from Git is that, because objects are addressed by hash, they can be stored in any DHT, and only refs must be stored in a distributed consensus data store.
In this blog post, I’ll be talking about the third component: hashsplitting. Hashsplitting, a concept borrowed from the bup backup utility, is a surprisingly simple technique which is capable of significant performance gains under the right conditions.
A little background: the git data structure, our modification and “blobs”
The basic git data structure consists of a directed acyclic graph with three node types, called “objects” in the Git documentation.
- Blob nodes store raw data. We have one blob per version of a file throughout the history of a repository.
- Subtree nodes represent directory structure, and map names to hashes of child nodes. Child nodes of subtrees may be blobs or other subtrees.
- Commit nodes store commit information, and denote a state of the git
repository that someone can
git checkoutand work with. As such they point to a number of parent commits as well as the base subtree of the current state of the git repository.
In a sort of Rusty pseudocode, we can roughly represent the structure of the git data structure like so:
enum Object {
Blob(Vec<u8>),
Subtree(HashMap<String, ObjectHash>), // Where hashes point to subtrees or blobs.
Commit {
author: String,
date: DateTime,
root: ObjectHash, // Points to a subtree.
...
}
}
And we can imagine the object store as a HashMap<ObjectHash, Object>, where
ObjectHash is a cryptographic hash of the bytes comprising the Object (in
Git, SHA-1 is used.)
Essentially, a subtree node in a git repository actually points to a copy of the entire directory structure it represents. The important part about this structure, though, is how two different commits can share various parts of their subtrees. Suppose we modify a single file in a directory containing several files. Then, that file’s hash changes; when we create a new subtree representing that directory and its files, we use the new hash for the modified file, but the unchanged files all have the same hashes from before and are thus already stored in the Git object store. When we commit this change, only the new file, subtree, and commit need to be stored anew.
(For more information on the git data structure, see this article.)
Our modification to the git data structure is to add an additional node type - the “multi-blob file”. A multi-blob file is similar to a subtree, except that it consists of an ordered set of pointers to either other multi-blob files or the original “small blob” from the git data structure. This lets multi-blob files share blobs between commits when changes are made; if we chunk extremely large files into small blobs, and then form large blobs from the smaller ones, we can avoid copying large amounts of data if the file is modified. The new structure looks roughly like this:
enum Object {
SmallBlob(Vec<u8>),
LargeBlob(Vec<(u64, ObjectHash)>), // Where hashes point to large blobs or small blobs.
Subtree(HashMap<String, ObjectHash>), // Where hashes point to large blobs or small blobs.
Commit {
author: String,
date: DateTime,
root: ObjectHash, // Points to a subtree.
...
}
}
The major difference is that small blobs no longer necessarily represent entire files - they may represent chunks of files. In our system, they will be on average about 3MB in size. The next obvious question is, how do we chunk large files so as to maximize sharing?
Chunking large files: interval-based splits
Suppose we chunk a large file by splitting it every 2MB. Each chunk becomes a small blob, and we build a tree of large blobs with small blob leaves to represent the large file. We might visualize this file as a list of chunks like so:
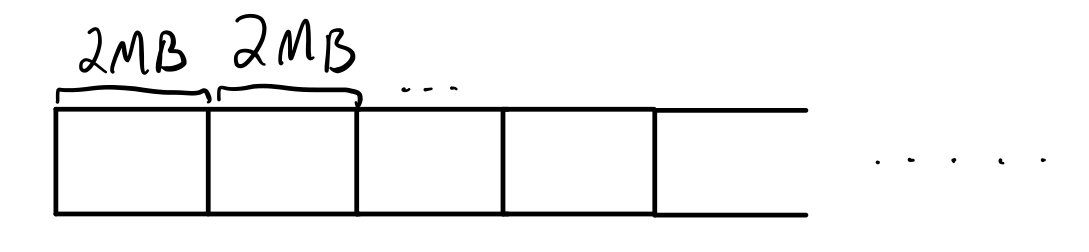
Now if we modify a chunk in the middle, only the modified chunk(s) need to be stored; the other chunks can simply point to the data of the old chunks:
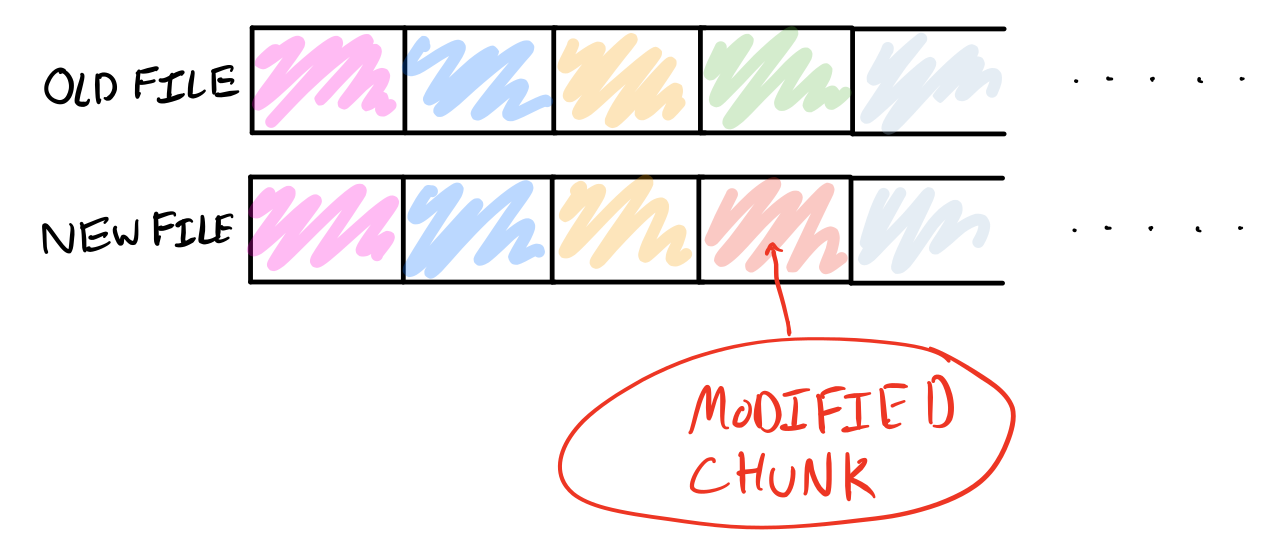
But suppose we shift an interval of the file a number of bytes closer to the beginning or end of the file, or perhaps copy a large earlier segment of the file to a later offset. What happens to the interval chunking scheme?
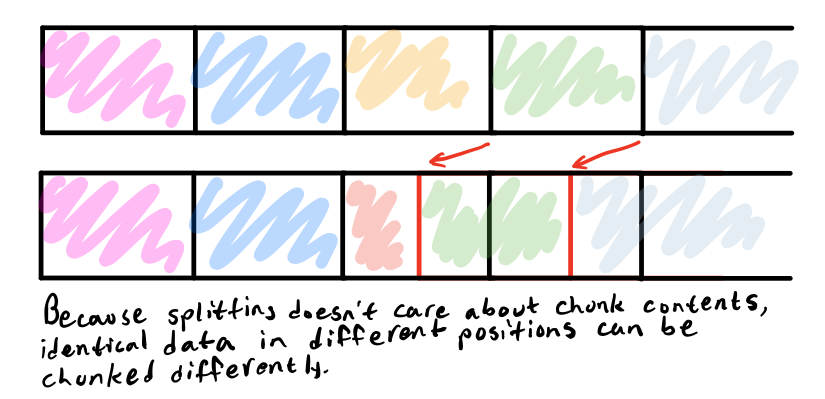
While the data stays the same, all chunks after the shift change because the splitting of the file doesn’t depend on the data being split, which means that all chunks after the shift need to be updated instead of just the range of changed data. Even though both files share a very large range of data, due to the chunking scheme, we still have to treat chunks within this range as different.
Chunking large files: deterministic splitting based on chunk contents
Hashsplitting is a method which is far more likely to produce chunks which contain identical contents. While hashsplitting a file, we maintain a rolling hash over a window of bytes (the size of which is tunable) and split the file at points where the hash passes some test: for example, in Attaca, we use divisibility by various powers of two, which can be written as a bitmask. With an interval-based chunking method, the chunk location depends strictly on how many bytes have been processed, total; however, with hashsplitting, the chunk location depends strictly on a window of previous bytes, meaning that inserting or removing bytes which are not part of the window causing the split - and which do not cause a new valid window for a split - will not change the split location.
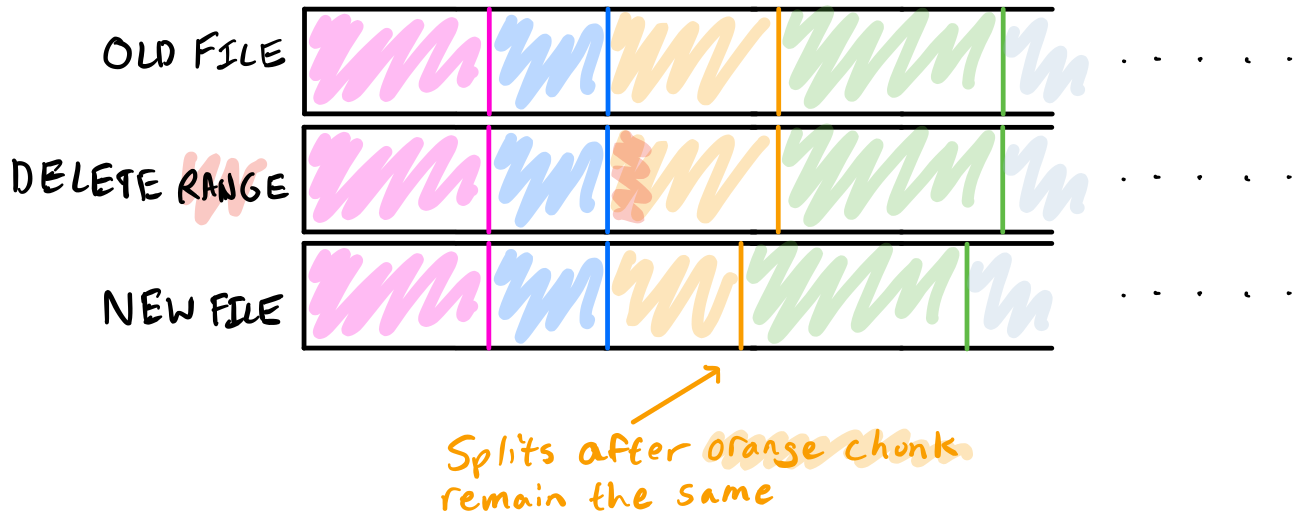
With hashsplitting, if a chunk in a file is shortened or lengthened, chunks other than the modified chunk will only change if a split marker is overwritten. This means that in the case of a repository with large amounts of similar data, the offsets at which these similar chunks occur will not change how their data is shared: splitting and sharing of blobs depends solely on the contents of the blob itself.
Attaca’s rolling hash is very simple, and identical to the one used by bup
and rsync: we sum all the bytes within a window, and check whether or not it
is divisible by a given power of two. This provides surprisingly regular
splits, roughly in the range of 16 to 128 KB with an average size of about 32
KB, and is easily fast enough to be I/O bound. An additional round of
hashsplitting can be done over a stream of chunks to create larger-sized
“chunks of chunks”, thus raising the average chunk size to about 3 MB, and the
lowest chunk size to about 512 KB and largest of about 32 MB. For the “chunks
of chunks” method we hash the individual chunks and re-run the hashsplitting
algorithm with smaller parameters, to try and produce lists of roughly 64
chunks in length. All in all hashsplitting is an easily adjustable and tunable
method - parameters can be adjusted to produce pretty much any distribution of
chunks you want.
Hashsplitting and Attaca
Attaca’s design uses hashsplitting for one especially specific reason: Attaca is designed to deal with extremely large files, on the order of gigabytes per file. The design goals of Attaca are to be able to handle repositories of up to a petabyte in size and individual commits in the range of terabytes; as such, any problems with interval chunking are magnified due to the sheer size of the files involved. Hashsplitting should also vastly increase sharing of small blobs because of the way that the chunking strategy depends on data.